2026知到答案 大模型应用实践(武汉晴川学院) 完整智慧树网课章节测试答案
第一章 单元测试
1、单选题:
下列优化器中,结合了动量法和 RMSprop 优点的是( )。
选项:
A:Adam
B:Adagrad
C:随机梯度下降
D:标准梯度下降
答案: 【Adam】
2、多选题:
以下关于“大模型”的描述中,哪些是正确的?
选项:
A:大模型能够处理更复杂的任务,具有更强的泛化能力。
B:大模型通常具有数亿到数万亿个参数。
C:大模型在推理时的计算需求相对较低。
D:大模型通常依赖于大规模的数据集进行训练。
E:大模型的训练数据通常较小,因此训练速度很快。
答案: 【大模型能够处理更复杂的任务,具有更强的泛化能力。;
大模型通常具有数亿到数万亿个参数。;
大模型通常依赖于大规模的数据集进行训练。】
3、判断题:
大模型在自然语言处理和计算机视觉领域的应用非常广泛,特别是在文本生成和图像识别任务中展现了其强大的能力。因此,大模型只能应用于这两个领域,而不适用于其他领域。
选项:
A:错误
B:正确
答案: 【错误】
4、单选题:
以下哪项最能描述大模型从神经网络到深度学习的演变过程?
选项:
A:大模型的发展主要依赖于增加数据量和计算能力的提升。
B:大模型的复杂性与传统机器学习算法无关。
C:大模型的发展不需要硬件的支持。
D:深度学习是神经网络的一种改进形式,主要通过增加网络层数来提升性能。
答案: 【深度学习是神经网络的一种改进形式,主要通过增加网络层数来提升性能。】
5、多选题:
以下关于大模型的历史背景与发展历程的描述中,哪些是正确的?
选项:
A:大模型起源于20世纪50年代的早期计算模型。
B:大模型的出现标志着计算机科学的停滞不前。
C:20世纪80年代,随着计算能力的提升,大模型得到了迅速发展。
D:大模型的发展与人工智能的萌芽有直接关系。
答案: 【大模型起源于20世纪50年代的早期计算模型。;
20世纪80年代,随着计算能力的提升,大模型得到了迅速发展。;
大模型的发展与人工智能的萌芽有直接关系。】
6、判断题:
深度学习的崛起主要得益于大数据的可用性和计算能力的增强,卷积神经网络(CNN)在图像识别领域的表现超越了传统的机器学习方法,因此可以认为卷积神经网络是深度学习的核心之一。
选项:
A:错误
B:正确
答案: 【正确】
7、单选题:
生成式预训练模型(GPT)主要通过什么方式来生成文本?
选项:
A:通过传统的规则和模板系统生成文本
B:通过简单的关键词匹配生成文本
C:通过人工输入每个字词来生成文本
D:通过深度学习模型,基于训练数据中的模式生成文本
答案: 【通过深度学习模型,基于训练数据中的模式生成文本】
8、单选题:
早期机器学习的发展受到计算能力和算法限制的影响。以下哪个选项最能反映计算能力对机器学习进展的重要性?
选项:
A:计算能力的提升使得更复杂的模型得以训练,从而提高了机器学习的效果。
B:计算能力对机器学习的进展没有显著影响,算法本身的创新才是关键。
C:早期机器学习依赖于简单的模型,因此计算能力的限制并未对其发展产生影响。
D:计算能力的不足导致了机器学习算法的逐步淘汰,无法适应新需求。
答案: 【计算能力的提升使得更复杂的模型得以训练,从而提高了机器学习的效果。】
9、单选题:
以下关于大模型的描述,哪一项是正确的?
选项:
A:大模型的训练数据量通常较小,主要依赖于人类手动标注的数据。
B:大模型仅限于自然语言处理领域,不能应用于其他领域。
C:大模型的计算效率高,适合在普通个人电脑上进行训练。
D:大模型通常指参数数量达到亿级或以上的模型,如GPT-3和BERT。
答案: 【大模型通常指参数数量达到亿级或以上的模型,如GPT-3和BERT。】
第二章 单元测试
1、单选题:
在数据预处理流程中,对于缺失值处理,当数据分布较为对称时,通常可采用( )填补。
选项:
A:中位数
B:均值
C:众数
D:插值法
答案: 【均值】
2、多选题:
以下属于数据预处理中数据变换操作的有( )。
选项:
A:数据标准化
B:数据归一化
C:特征选择
D:数据重复处理
E:缺失值填补
答案: 【数据标准化;
数据归一化】
3、判断题:
在数据分割时,常用的数据分割方法有随机分割、交叉验证和留一法等,且选择合适的分割方法对模型性能评估影响不大。( )
选项:
A:错
B:对
答案: 【错】
4、单选题:
预训练模型中,在自然语言处理领域获取语言深层次理解能力的模型是( )。
选项:
A:GPT(这里假设学生需明确 BERT 在自然语言处理的典型性)
B:VGG
C:ResNet
D:BERT
答案: 【BERT】
5、多选题:
下列关于模型训练优化方法的描述,正确的有( )。
选项:
A:网格搜索在任何情况下都是最有效的调参方法
B:分布式训练中数据并行不会面临任何问题
C:学习率衰减是一种常用的学习率调整策略
D:早停策略可通过在验证集上监控模型性能来避免过拟合
E:正则化方法如 L1、L2 正则化可防止模型过拟合
答案: 【学习率衰减是一种常用的学习率调整策略;
早停策略可通过在验证集上监控模型性能来避免过拟合;
正则化方法如 L1、L2 正则化可防止模型过拟合】
6、单选题:
若有两个向量 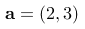 和
和 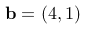 ,则它们的点积为多少?
,则它们的点积为多少?
选项:
A:8
B:14
C:6
D:10
答案: 【14】
7、多选题:
以下关于批归一化和层归一化的说法中,哪些是正确的?
选项:
A:层归一化的计算不依赖于批次大小,适合多种场景。
B:批归一化在每个批次上计算均值和方差,适用于小批量数据。
C:批归一化会导致训练过程中出现不稳定,尤其是在小批量情况下。
D:层归一化在每个样本上计算均值和方差,适用于序列数据。
答案: 【层归一化的计算不依赖于批次大小,适合多种场景。;
批归一化在每个批次上计算均值和方差,适用于小批量数据。;
层归一化在每个样本上计算均值和方差,适用于序列数据。】
8、判断题:
归一化技术在深度神经网络的训练中可以有效提高模型的训练速度和稳定性,减少梯度消失和爆炸的问题,因此在任何情况下都必须使用归一化技术以保证模型的性能和收敛性。
选项:
A:正确
B:错误
答案: 【错误】
9、单选题:
批归一化的一个主要优点是它可以加速模型的收敛速度。以下哪个选项最能说明批归一化的作用?
选项:
A:通过减少训练数据的需求,降低了需要的计算资源。
B:通过增加模型的复杂度,使得优化过程中更容易找到全局最优解。
C:通过提高模型的非线性能力,使得模型可以处理更复杂的数据。
D:通过标准化每一层的输入,减少了内部协变量偏移,从而加速收敛。
答案: 【通过标准化每一层的输入,减少了内部协变量偏移,从而加速收敛。】
10、单选题:
在前馈神经网络中,信息是如何流动的?
选项:
A:信息在输出层反馈到输入层
B:信息在网络中是双向流动的
C:信息只从输入层流向输出层
D:信息只在隐藏层之间流动
答案: 【信息只从输入层流向输出层】
11、单选题:
在Transformer模型中,Encoder的主要作用是什么?
选项:
A:通过特定算法实现自我学习,更新模型参数。
B:对输入序列进行编码,提取特征信息以供后续处理。
C:仅用于数据预处理,不参与模型的主要计算。
D:生成输出序列,直接与目标序列匹配。
答案: 【对输入序列进行编码,提取特征信息以供后续处理。】
12、判断题:
在Transformer模型中,自注意力机制是使模型能够在处理输入序列时关注序列中不同位置的信息,从而提高模型对上下文信息的理解能力。因此,自注意力机制是Transformer模型的核心部分,缺少自注意力机制则无法实现Transformer的功能。
选项:
A:正确
B:错误
答案: 【正确】
13、多选题:
自注意力机制在处理长文本时,计算复杂度为O(n²)。以下哪些选项正确描述了这种计算复杂度对模型性能的影响?
选项:
A:当文本长度增加时,计算复杂度也会显著增加,导致模型训练时间变长。
B:O(n²)的复杂度使得模型在处理长文本时可以有效捕捉句子间的依赖关系。
C:计算复杂度的增加可能导致内存消耗显著增加,从而限制可处理的文本长度。
D:较高的计算复杂度通常不会影响模型的推理速度。
答案: 【当文本长度增加时,计算复杂度也会显著增加,导致模型训练时间变长。;
计算复杂度的增加可能导致内存消耗显著增加,从而限制可处理的文本长度。】